
.__.
[BRS with ML and AI] 3. Evaluating Recommeder Systems | 추천 시스템 평가하기 본문
[BRS with ML and AI] 3. Evaluating Recommeder Systems | 추천 시스템 평가하기
yesjiyoung 2022. 6. 23. 09:363.1 Train/Test and Cross Validation | 학습/테스트 데이터와 교차검증
- Train / Test 분리

- 검증 방법 : k-fold validation
-> 학습 데이터의 개수가 적은 경우 사용하면 좋다.
-> 과적합 방지용
3.2 Accuracy Metrics (RMSE, MAE) | 정확도 지표(RMSE, MAE)
| mean absolute error (MAE)
| root mean square error (RMSE)
- 예측과 실제의 차이가 크면클수록 더 높은 페널티를 부여받는다.
- 예측과 실제의 차이가 작으면작을수록 더 낮은 페널티를 부여받는다.
+ Netflix Prize는 넷플릭스 사용자들의 영화 별점 데이터를 가지고 2006년 10월부터 2009년 7월까지 약 3년에 걸쳐 이어진 기계학습을 통한 영화 평가 데이터 예측 대회
+ 넷플릭스는 우승자의 연구물을 사용하지 않음. (결국 넷플릭스가 중요하게 생각했던 것은 어떤 영화들을 최고의 추천자 목록에 올려 놓았는가와 그 영화들이 추천된것을 보았을 때 그 사용자들이 어떻게 반응하느냐 였다.)
3.3 Top N Hit Rate - Many Ways
| Hit Rate (적중률) : 전체 유저 수 대비 적중한 유저 수 (* 한 번이라도 클릭하면 적중했다고 보나? -Yes)
-> 자세한 설명 : https://sungkee-book.tistory.com/11
[추천시스템] 성능 평가 방법 - Precision, Recall, NDCG, Hit Rate, MAE, RMSE
[추천시스템 시리즈] 2021.08.30 - [데이터과학] - [추천시스템] 비개인화 추천 알고리즘 - 인기도 기반 추천 2021.09.01 - [데이터과학] - [추천시스템] 성능 평가 방법 - Precision, Recall, NDCG, Hit Rate, MA..
sungkee-book.tistory.com
Just add up all of the hits and your top-n recommendations for every user in your test set, divide by the number of users and that's your hit rate. (?)
개별 사용자에 대한 상위n개 목록의 정확도
| Hit Rate with leave one out cross validation
방법
1) 사용자가 선호한 아이템 중 1개를 제외한다.
2) 나머지 아이템들로 추천 시스템을 학습한다.
3) 사용자별로 K개의 아이템을 추천하고, 앞서 제외한 아이템이 포함뙤면 Hit이다.
4) 전체 사용자 수 대비 Hit 한 사용자 수 비율을 구하면 Hit Rate!

| Average Reciprocal Hit Rate(ARHR)

- 하단 슬롯보다 상단 슬롯에서 성공적으로 아이템을 추천한 것에 대해 더 큰 크레딧을 받는다.
- 적중 여부만을 고려하는 것이 아닌, 적중의 순위와 그에 따른 패널티가 고려된다..
|Cumualative Hit Rate(cHR)

- Hit Rate을 계산할 때,임계치보다 낮은 항목을 추천하는 것은 히트로 보지 않는다. (계산 과정에서 배제)
| rating Hit Rate(rHR)
- 예상 등급 점수로 분류하는 것.
-> 적중률이 높고 RMSE 점수가 낮으면 추천 시스템을 구축 할 수 있습니다. RMSE와 적중률은 다르므로 RMSC와 적중률은 관련이 없습니다.
3.4 Coverage, Diversity, and Novelty
추천 시스템에서의 정확도 이외의 중요한 지표들이 많다(3.4 ~ 3.5)
| Coverage | 적용범위
- 추천시스템이 (user, item) 제공할 수 있는 추천의 비중 ex) 전체 유저 중에서 몇 명의 유저까지 추천 서비스를 제공할 수 있는지
- Coverage 와 Accuracy는 trade off !
- 더 높은 추천 품질을 위해서, 임계값을 높이면, 정확도는 올라가지만, 커버리지는 떨어진다.
ex) 새 책은 어떤 유저가 그것을 구입하고 패턴이 새일 때까지 추천 목록에 절대 들어갈 수 없게 된다. (커버리지가 낮아진다.) - long-tail items가 있도록 시스템을 설계할 필요가 있다.
| Diversity | 다양성
- diversity = 1 - Similarity
- Diversity <-> Similarity
- 주의해야할 점은 완전히 무작위적인 것을 추천하여 높은 다양성을 달성할 수 있는데 그것은 좋은 방법이 아니다!! => 비정상적으로 높은 다양성은 나쁜 추천으로 이어짐.
| novelty | 참신성
- 참신성.. 말이 좋은 것 같지만 꼭 그렇지는 않다 .
- 추천 아이템이 얼마나 인기있는지를 함께 고려해야하기 때문이다!!
- 여기서 User Trust (유저의 신뢰) 라는 부분을 염두해두어야한다.
- 유저 입장에서 유명한 아이템을 추천받으면 좋다고 믿고, 유명하지 않은 아이템을 추천받으면 나쁘다고 믿는다.
-> 그래서, popular items와 novelty items사이의 균형이점을 찾아야 한다.
- The Long Tail
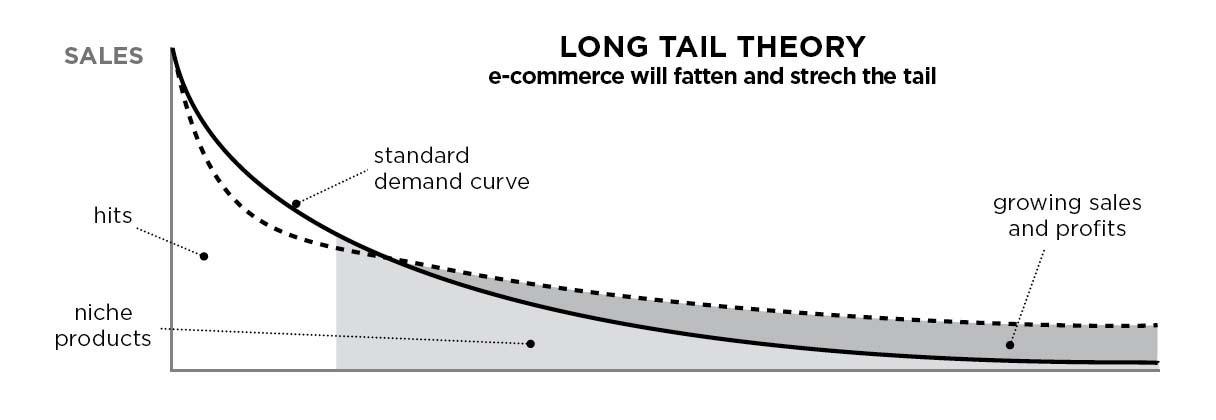
-> novelty score가 높은 추천시스템은 세상을 더 나은 곳으로 만들 수는 있다.
-> 그치만, it is more important strike balance between Novelty and Trust.
3.5 Churn, Resposiveness, and A/B Tests
|Churn | 이탈성
- 얼마나 추천시스템이 자주 바뀌는가
- 유저가 새 영화를 평가하면 추천 항목이 크게 바뀌는가? -> 그렇다면 이탈성(이탈점수)가 높은 것이다.
- 항상 같은 대상을 추천해주는 것은 좋지않다. 그렇지만 Diversity와 Novelty와 마찬가지로 이탈 점수가 좋은 것은 아니다!! 무작위로 추천해줘도 이탈점수가 높게 나옴 그래서 좋지 않음.
★ 측정 항목은 함께 살펴봐야하며 측정항목 간의 균형을 이해하는 것이 중요!
| Responsiveness | 응답성
: 새로운 유저의 행동이 추천에 얼마나 빠르게 영향을 미치는지 측정
: churn 점수와 유사할 수 있음. 하지만 가장 큰 차이점은 응답성은 시간으로 측정이되고, 이탈점수는 변경의 횟수로 측정된다.
: 다시말해서, 응답성은 시간("얼마나 빨리" 변경이 이루어지는)로 측정되고, 이탈성은 변경 횟수("얼마나 자주" 변경이 이뤄졌는지)로 측정된다.
-> 높은 응답성은 좋은 것이지만 비지니스 세계에서는 그에 맞는 적절한 응답성을 결정하는 것이 중요할 것이다.
| 결론
- 지금까지 더 나은 추천시스템을 구축하기 위해 평가지표들을 살펴보았는데, 결론은 지표들은 항상 함께 살펴봐야 하고 그들 사이의 절충점을 늘 고려해야한다.
- 추천시스템의 요구사항과 주요한 목표에 초점을 맞추어야한다.
- 근데 제일 중요한건.. 실제 사용자들의 피드백 결과이다. -> A/B테스트가 짱이다.
| A/B Tests |
- 고객이 우리가 만든 추천시스템에 어떻게 반응하는지가 훨씬 중요함.
- 앞서 소개한 지표들의 성능만 좋아서는 안됨. 온라인에서 얼마나 잘 작동하고 좋은 피드백이 오는 지. 그런것들을 확인하는게 더더 중요함.
'추천 시스템 > BRS with ML and AI' 카테고리의 다른 글
| (SKIP!!) [BRS with ML and AI] 2. Introduction to Python (0) | 2022.06.22 |
|---|---|
| [BRS with ML and AI] 1. Getting Started (0) | 2022.06.16 |
